
YANG Cheng
I did my master degree at school of EIC, Huazhong University of Science and Technology(HUST) , Wuhan, China, in 2021, where I was advised by Prof. Peng Guo. I did my bachelors at school of Information and Intelligence, Hunan Agricultural University(HUNAU) , Changsha, China, in 2018.
News
Experiences
I am curious about many things when I am a student. Also I wanted to find a research direction that suits me. During undergraduate to master study, I have learned embedded development, software development, computer vision and other related technologies. My experiences and projects are as follows.
Model compression in Habitat-Lab(PointGoal navigation)
Based on Reinforcement Learning, I combined model pruning and habitat for pointGoal navigation tasks.
By using previous pruning method, The ResNet50-Pruned could achieve a better performance than the ResNet50-Baseline,
but with significantly fewer FLOPs and Parameters.
I also found some painful problems. For more experimental details, please see my report document.


When we deploy neural network models, we have to face their high computational cost and memory footprint. It seems that we have to make a strict choice between hardware cost and accuracy. But we know almost all models have many redundent parameters. I summarized 6 methods of model pruning and 3 methods of model knowledge distillation as mainly benchmarks in YoLov5. In short, I implemented reduce FLOPs and Parameters by about 35% without negatively impacting the mAP by using those methods. The detailed benckmarks will coming.
General classification and detection tasks
Based on my PyCR(Pytorch for Classification and Retrieval) pipeline and YoLov5 detector, I solved some projects about classification(Fallen trees, Vegetation destruction with weak supervision, road slogan, 20+ types of vehicles and so on) and detection(general traffic, fire, fumes, dust) tasks. By using it, I can achieve high accuracy(98+%) easily and quickly in these projects.
Optimize classification models
Those projects aim to optimize some classification models, such as the "Cyclist and pedestrian
classification model"
In this project of ReID, I only used 3w imbalanced( cyclist: pedestrian ~ 1:30)
images to complete the classification of 300w images. Through research-related work, such as GAN, and image
composition,
I proposed a method called 'Copy and Paste Based on Pose(CPP)', which can effectively
alleviate the sample imbalance problem in this situation.
Then I used a simple model(EfficientNetB5) and corresponding training skills to achieve classification
accuracy of 99.6%. For detailed information about CPP, please see
arXiv for more detail information.
The Commodity Automatic Checkout Counter

This project aims to achieve high-precision commodity bill settlement. When users place the dinner plate
under its camera, it will quickly automatically generate the correct bill within 1 second.
For me,
I was responsible for its visual processing, such as commodity detection and classification. In
order to make it work more stable, I combined object detection and retrieval to solve the problem and avoid
frequent updates of the model. Specifically, I decoupled the problem of commodity detection into two
sub-problems of object detection and object retrieval.
The detection model is responsible for detecting the foreground object, and the retrieval model is
responsible for identifying the category of the object.
The final overall accuracy can reach 98%+.
I used YoLov3 as the basic detection model in this project. By following the
progress at that time, and making
trade-offs in inference time and accuracy, I added SPP, DCN, and IOU Aware to
YoLov3 to improve
detection accuracy. In addition to this, I used ResNeXt101 as the basic
classification model. and the output from
pool5 is used as the metric vector during retrieval. To improve the accuracy of retrieval, I
add double loss(Softmax loss, Triplet loss) to restrict feature space, which leads
to the model output with a larger inter-class
variation and a smaller intra-class variation.
Cross-platform Tencent Cloud image and speech processing interface tool
This project aims to design cross-platform image and speech processing interface tool based on Golang. Because for the convenience of users to use some image and speech processing services, I wanted to design a cross-platform tools, which allowed users to experience many basic services that deployed on cloud servers, no matter what operating system they used(Windows, Linux, Mac). And These services include image recognition, image detection, speech recognition, OCR, etc.
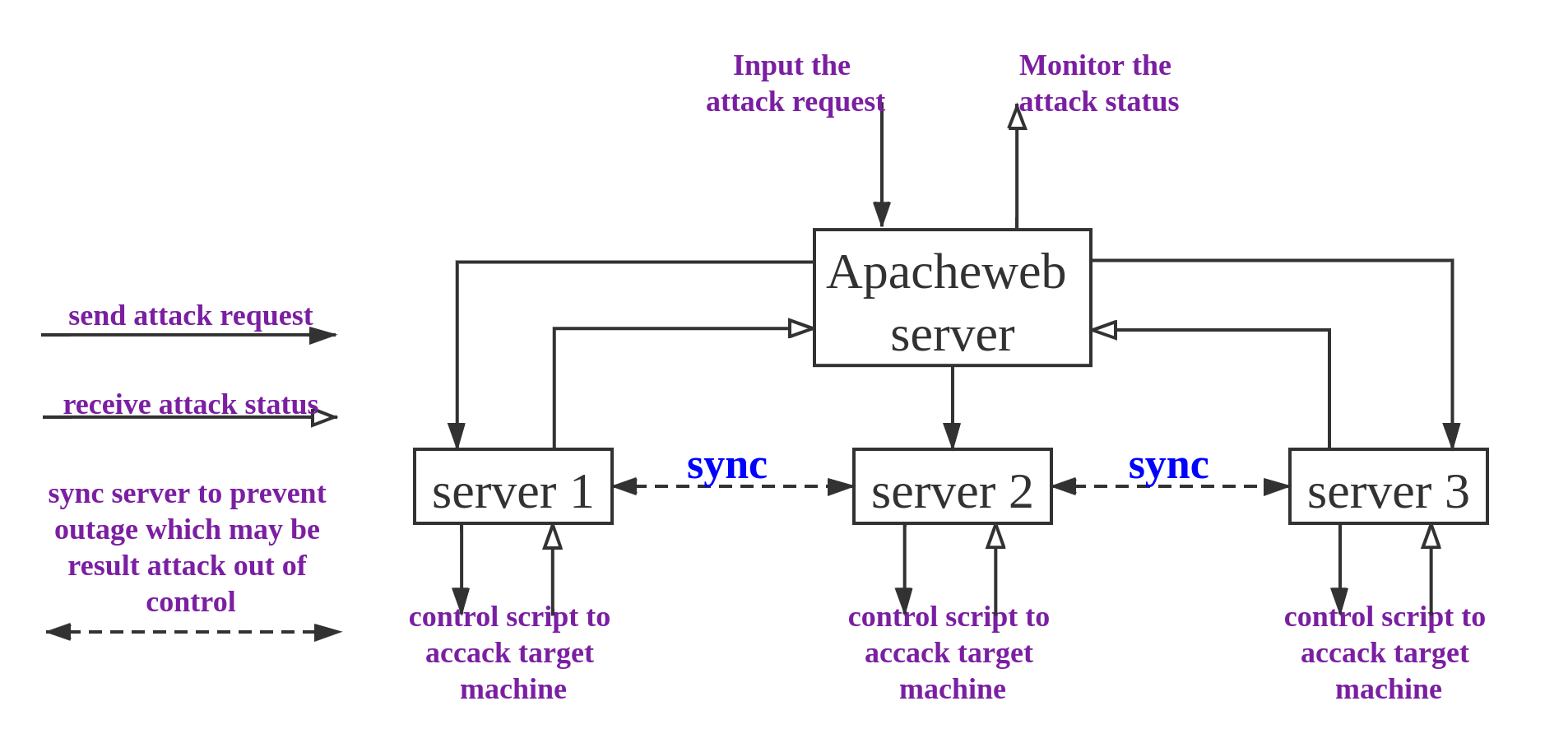
In this project, I was responsible for the front-end and back-end programs. When users input the attack request with specific parameters to the web, the web server will forward the request to the corresponding server. Then, the server is a Zombie computer to call the corresponding script to attack the target machine. And the server reflects the attack status in real-time to the web for a display to users. Last but not least, in order to maintain control of the attack state and ensure the reliability of the system, even if the corresponding server suddenly outage, I must keep in sync between different servers.
Competitions
This is an object detection task about Wheat Detection, and we(2 people in the team) need to mark all the
wheat heads in echo images. The metric is mAP@[.5:.75], and the AP = TP / (TP + FP + FN). We only used one
2080Ti GPU
step 1) Choosing the yolov5 as ours basic model;
setp 2) Data preprocessing, anchor re-clustering and model training: the Mosaic and albumentations, label
smoothing, EMA as so on;
step 3) Simple parameter adjustment: find a better Iou threshold when calculating nms;
step 4) Post-processing: TTA + WBF + PL + OOF;
step 5) Analyzing some badcases: We found that there are some redundant prediction bounding bbox when the
wheat occlusion is serious. So we summarized the corresponding rules and peform filtering.
In conclusion, It was the first time I participated in the competition. Some time after that, I
re-summarized the competition, and found some error methods, such as only adjusting iou threshold is the
wrong way, analyzing
badcase and setting some rules to 'solov' the misdetection will undoubtedly only lead to over-fitting
results. This experience taught me that when analyzing problems, we must learn to consider from a macro
perspective. At the same time, the analysis of badcase should not be discussed separately from model and
loss.
BTW, The controversy caused by yolov5 is too great, our results is were cancelled. If not, our score should
be in the top 2%.
Projects
In the second half of the master's career(01/2020 ~ 06/2021), I mainly focus on computer vision, and take it as my research direction. In the first half of the master's career(09/2018 ~ 12/2019), I mainly focus on hardware programming, embedded development, software development, and have learned some hardware-related knowledge. At the same time, my master's dissertation is also closely related to them.
PyCR(Pytorch for Classification and Retrieval)
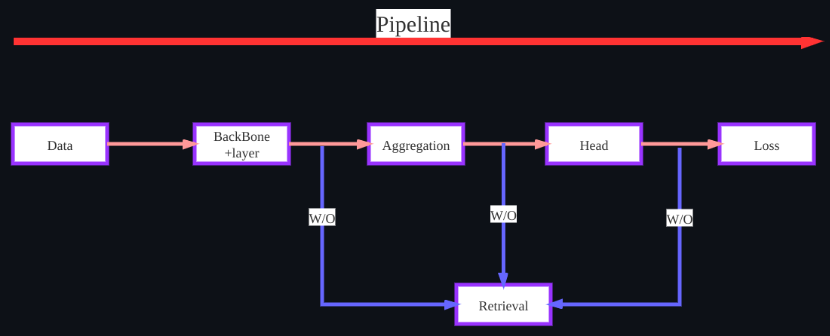
When I finished the HuaWei's competition, I started to think about how to complete some tasks efficiently.
When I finished the competition, I started to think about how to complete some tasks efficiently.
The classification and retrieval are familiar to me, So I was thinking about how to build a
pipeline, which can make me implement these functions better and faster.
At this stage, there is no pipeline that directly merge classification tasks and retrieve tasks. For
example, FastReID is a framework for end-to-end retrieving in ReID, PyRetri is a pipeline that directly
uses features for post-processing, and does not involve the training process. So, I have build a pipeline,
which can do the end-to-end processing of classification and retrieval respectively.
For detailed processing methods, please see github.
Design and Implementation of a low-complexity wearable system for football sports monitoring
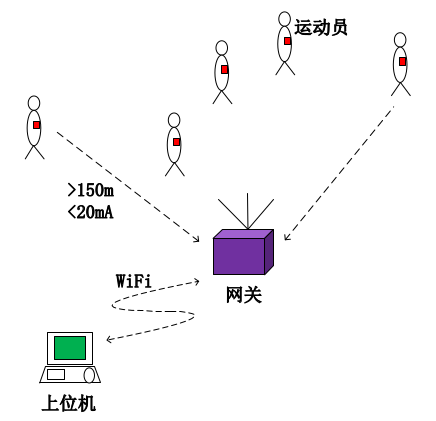
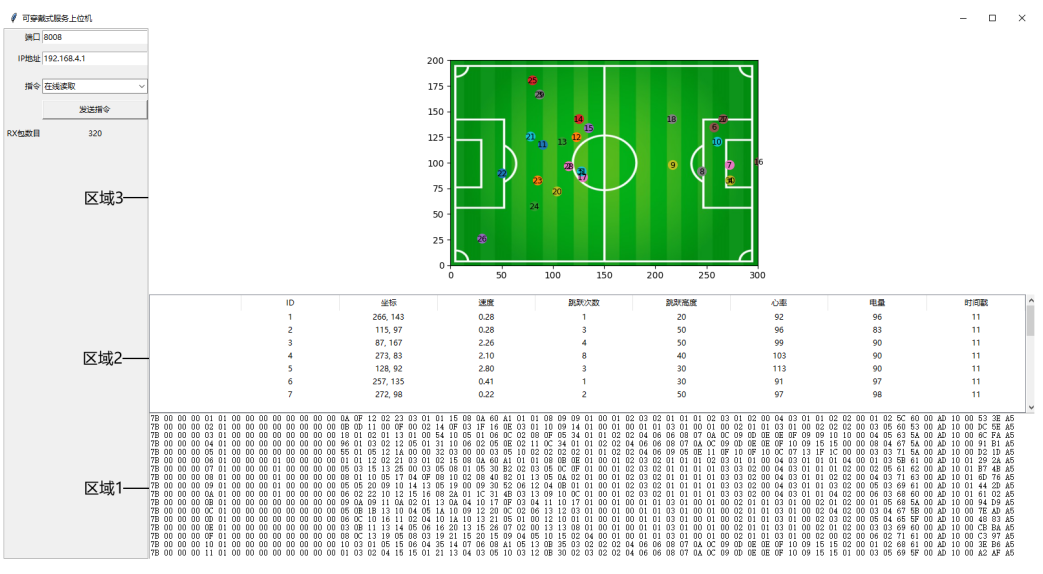


This is research topic, but also a project. Its goal is to design a low-complexity, low cost and
high-efficientcy(QPS) product which serves group sports monitoring. It's mainly to monitor some
pyhsical information of athletes, such as speed, heart rate, real-time position, number of jumps and height,
etc.
The projects is divided into three parts, which include a lot of collection nodes(30+), the gateway(1), and
display terminal(1). Each collection nodes is composed of CC1310 and a variety of sensors, which are
used to collect real-time physical data of athletes. The gateway is mainly composed of STM32, multiple
CC1310, ESP8266 and other auxiliary chips(FLASH, Power management). The function of the gateway is
is responsible for transmission of data from multiple nodes to the display terminal and distribute commands
from the terminal to all nodes. The display terminal is responsible for some command control and
visualization of data from the multiple nodes. Each parts is implemented based on the corresponding Finite
State Machine.
To guarantee the stability of the system, low complexity(~$300), high access volume(~1Hz), long-distance
communication(>150m) and low power consumption(<2mA) functions, I have completed the corresponding hardware,
software and
communication and data processing algorithm design. Please see my
master's dissertation
for the detailed informations.
Last but no least, Although this is my master's dissertation, I would like to think my senior Liu for his
helped in high-frequency circuit design, and thank my classmates for testing with me and helping me find
bugs,
and thank my supervisor Peng Guo for his long-term guidance.
Skills
Awards
Vistors Map
